Data augmentation using few-shot prompting on large Language Models
Why do we need augmentation?
Deep learning revolutionized the field of natural language processing and made a variety of complex tasks much easier to perform. Large annotated datasets play a critical role in this success since deep learning models need a lot of data to be trained on.
However, it is sometimes difficult and expensive to annotate a large amount of training data. Therefore, proper data augmentation is useful to increase the model performance 💪.
Many text augmentation techniques have been proposed like:
Meanwhile, new large-scale Language Models (LMs) are continuously released with capabilities ranging from writing a simple essay to generating complex computer codes — all with limited to no supervision. So, the following question arises: Can we make use of large-scale LMs for text augmentation 🤔?
Large-scale LMs to the rescue!
Recently, many studies have shown that large LMs that use only the decoder part of a Transformer (autoregressive models) are excellent few-shot learners allowing them to be controlled through natural text. So, we can leverage the few-shot capabilities of large LMs for generating synthetic realistic data. The secret here is prompt engineering!
Basically, we utilize a prompt which consists of:
- A general description of the task
- A pair of annotated samples from the training set
For a text classification task, we can create the following prompt:
Each item in the following list contains a <text type> and the respective <label type>. <label type> is one of ’<label token 1>’, …, or ’<label token N>’.
<text type>: <example text 1> (<label type>: <example label 1>)
<text type>: <example text 2> (<label type>: <example label 2>)
<text type>:where <text type> , <label type> and <example label i> should be properly defined in each case.
That’s all! Overall, to generate synthetic samples we need 3 ingredients:
- A large-scale LM to leverage its few-shot capabilities.
- A small dataset that we want to augment.
- A properly designed prompt.
The bottom figure summarizes the procedure:
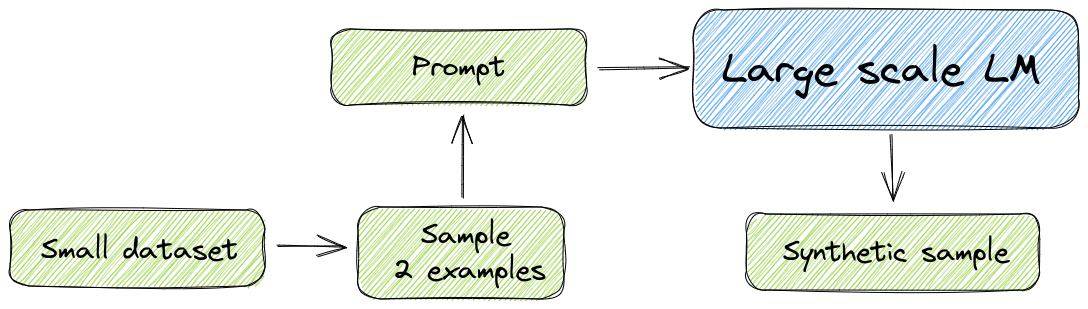
More technical details on text augmentation using large-scale LMs can be found on the GPT3Mix paper.
Dataset and Model
To investigate the benefits of our approach, we need a relatively small dataset. We will use the Emotion dataset that is available on Hugging Face 🤗. It contains English Twitter messages labeled as one of the six basic emotions: anger, fear, joy, love, sadness and surprise. To reduce the complexity of the task, we will keep only three labels, namely:
- joy 😂
- anger 😠
- surprise 😯
The dataset is already split into 16,000 train and 2,000 test samples. To investigate the effectiveness of the augmentation method, we will use only 10 samples per class as a training set. A sample looks like this:
Tweet: I feel angered and firey
Label: Angry
For our task, the prompt looks like this:
Each item in the following list contains a tweet and the respective sentiment. Sentiment is one of ’joy’, 'surprise' or 'anger'.
Tweet: i feel angered and firey (Sentiment: anger)
Tweet: im feeling very peaceful about our wedding again now after having (Sentiment: joy)
Tweet:We will train a DistilBERT model, which is a light Transformer trained by distilling BERT base. It has 40% fewer parameters than bert-base-uncased, runs 60% faster while preserving over 95% of BERT’s performances as measured on the GLUE language understanding benchmark.
Our next step is to find a large-scale LM!
The famous one: GPT-3
We’ll start with GPT-3 that is by far the most famous LM. It has 175 billion parameters and was trained with data from CommonCrawl, WebText, Wikipedia, and a corpus of books. It was released by OpenAI and is considered as a “tremendous leap for AI” due to its amazing performance on various tasks in the few-shot setting (and in some cases even in the zero-shot setting).
Below, we can see a visual example of using GPT-3 for text augmentation:

To access GPT-3 we will use OpenAI’s API. First, we need an API key though the OpenAI website. Then, we can make a request for text completion by giving as input our designed prompt. The code is shown below:
For the full code on data loading, text augmentation and model training/evaluation check our GitHub repo.
After we generate 10, 50, 100 and 200 synthetic samples, we train our model on the different augmented datasets. The accuracy curve is shown below:

The accuracy of the model increases as we augment more and more data! After generating 200 extra synthetic samples, the accuracy exceeds 70% indicating that text augmentation can greatly improve the accuracy of our model.
Let’s print some synthetic tweets generated by GPT-3!
Tweet: even if ur not into these kind of things u have to admit it’s pretty cool
Label: joy
Tweet: i’ve had this knot in my stomach all week. i thought it was indigestion
Label: anger
They are very realistic and you probably can distinguish if they are synthetic of real samples!
However, GPT-3 comes with a main drawback. It is not openly available and we need a paid API to access it.
Let’s go open-source: GPT-Neo & GPT-J
Luckily, there are open-source alternatives! Eleuther AI is a group that tries to democratize huge LMs made GPT-Neo and GPT-J publicly available.
Both models are available through Hugging Face. Here, it should be noted that to load the models for inference, we need 25 GB of CPU RAM for GPT-Neo and 48 GB of CPU RAM for GPT-J. The code is shown below:
Let’s have a look at the accuracy curves of the open-source alternatives!


The results of GPT-Neo are worse (left diagram). The performance of the model decreases when we train in on synthetic data (except in the case of 50 synthetic samples).
On the other hand, the accuracy curve of GPT-J is awesome (right diagram). Each time we increase the size of the training set with synthetic samples, there is a consistent increase in the accuracy reaching 85%.
Let’s print some synthetic tweets generated by GPT-Neo
Tweet: happy friday :)
Label: anger
and GPT-J.
Tweet: i think it s the easiest time of year to feel dissatisfied
Label: anger
GPT-J manages to generate high quality samples while GPT-Neo have generated a sample with a wrong label.
Let’s compare all models together in one diagram!
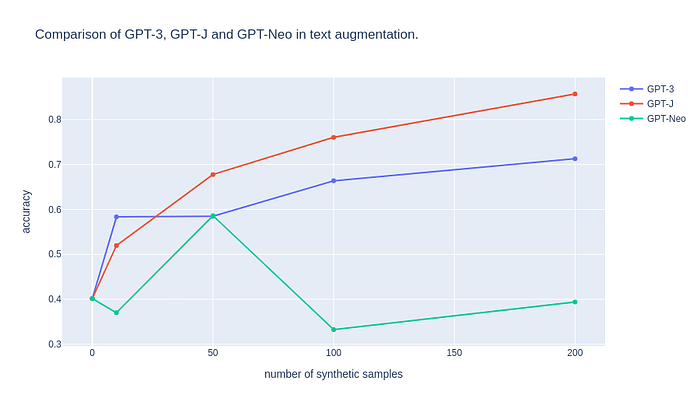
Awesome! GPT-J outperforms GPT-3 in almost all different versions of the dataset 👏. These are very exciting results that indicate that we can use the open-source GPT-J instead of GPT-3 for text augmentation.
As for GPT-Neo, it performs very poorly mainly because it is much smaller than GPT-J (2.7 billion parameters in contrast to 6 billion).
Does augmentation solve everything?
Our text augmentation method increases the model performance by a large margin! When we generated 200 synthetic samples, we managed to double the accuracy. So, why don’t we generate more and more synthetic data to reach an even higher performance?
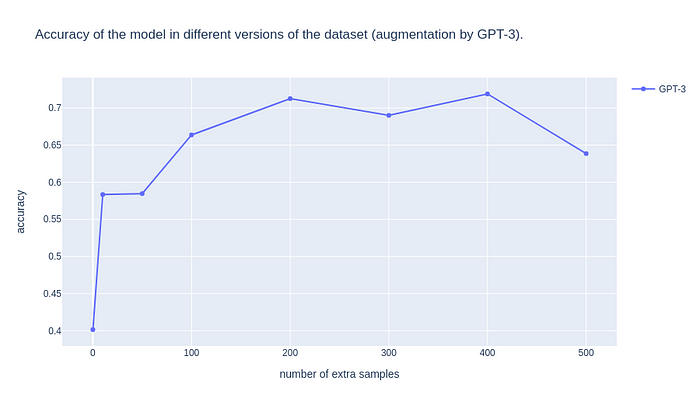
In the above figure, we generated 300, 400 and 500 synthetic samples. We observe that the accuracy stops increasing at some point (200 synthetic samples), then stabilizes and at the end it even decreases.
Hence, we realize that text augmentation can improve performance until some point. Then, the synthetic samples are not so diverse, hurting the generalization capability of the model.
Label Distribution
Now let’s see how the distribution of the labels changes when we generate more and more synthetic samples.
As a reminder, our baseline training set is balanced since it consists of 10 samples per class. When we generate 200 synthetic samples, we have a new training set of 230 samples.
In the figure below, we see how the distribution of the labels changes after text augmentation.

We observe that the new label distribution differs a lot from the baseline and the augmented dataset is highly imbalanced in all cases! The GPT-3 model generated too many samples labeled as ‘anger’ while GPT-J and GPT-Neo generated more samples labeled as ‘surprise’.
To interpret this behavior we should look into the datasets that these LMs are pre-trained on. Since GPT-J and GPT-Neo are trained on the same dataset, they shift the label distribution in the same way. That’s an important issue that we should always take into account when we perform text augmentation!
There are many techniques to deal with the label imbalance problem (resampling, ensembling etc) that can increase the accuracy even more. However, we won’t discuss them in detail in this blogpost.
Wrapping up
In this blog post, we leverage the few-shot capabilities of large-scale LMs to perform text augmentation on a very small dataset. Our main conclusions follow:
- Text augmentation using large LMs and prompt engineering increases the performance of our classification task by a large margin.
- Open-source GPT-J performs better than closed-source GPT-3 in our case and can be used as an alternative for text augmentation.
- There is a limit on the accuracy improvements that text augmentation can introduce.
- The synthetic datasets are not balanced anymore because large LMs are prone to generate samples with certain labels based on the data they are trained on.
In all cases, make sure to test out multiple language models as our results are highly dependent on the LMs leveraged. In our example GPT-Neo actually decreased the accuracy and GPT-J performed better than GPT-3. Stay tuned for more blogposts on this topic!
Full code is available here.
About ML6
We are a team of AI experts and the fastest-growing AI company in Belgium. With offices in Ghent, Amsterdam, Berlin, and London, we build and implement self-learning systems across different sectors to help our clients operate more efficiently. We do this by staying on top of research, innovation, and applying our expertise in practice. To find out more, please visit www.ml6.eu
